As a Product Manager, your ability to ship impactful features is directly tied to the health of your codebase. Technical debt isn't an "engineering problem"—it's a strategic liability that silently kills your roadmap and burns out your best talent. I've seen promising products at companies like Google and Meta grind to a halt because PMs failed to treat tech debt as a first-order business problem.
The key is to stop treating it as an abstract complaint and start managing it like a portfolio. This playbook gives you a step-by-step system to make debt visible, quantify its business cost in dollars and time, and strategically prioritize fixes alongside new features. This is how you move from feature manager to true product leader.
Why Technical Debt Is a Product Manager's Problem
You live and die by your ability to ship features that users love and that move the needle on revenue and growth. Technical debt is the single biggest threat to that mission.
It’s not some abstract engineering issue you can afford to ignore. Think of it as a direct tax on your team's velocity and your product's future. When your engineering lead says, "we're slowing down because of tech debt," what they're really telling you is that your entire roadmap is at risk.
Ignoring this is a classic PM failure mode. I’ve seen promising products at fast-growing startups grind to a halt because the PMs decided tech debt was "engineering's problem." They failed to grasp that every shortcut taken to hit a deadline, every outdated library left untouched, and every poorly designed component accumulates "interest." That interest gets paid in the form of slower development cycles, more bugs, and frustrated engineers—the very people you need to build your vision.
The True Cost of Technical Debt
The operational drag from technical debt is staggering when you actually look at the data. That feeling of a slowdown isn't just in your head—it's a measurable drain on productivity.
One Developer Report found that developers spend 23% to 42% of their time just managing technical debt. That’s nearly half of every workday swallowed by work that doesn’t directly build new value. It gets worse. A shocking 87% of CTOs surveyed in a McKinsey Tech Debt Study cited technical debt as their main barrier to innovation. You can read the full research about technical debt's impact to dig deeper.
For Product Managers, this pain shows up in a few specific ways:
- Unpredictable Timelines: Your roadmap commitments become pure guesswork. A two-week feature suddenly takes a month, eroding trust with stakeholders. This is a career-limiting problem for a PM.
- Decreased Innovation: Your team is stuck fixing old problems instead of building the AI-powered features or new user experiences that will differentiate your product in the market.
- Lower Team Morale: Talented engineers get demoralized fighting the codebase just to make basic progress. This leads to burnout and attrition, putting your team's talent—and your ability to execute—at risk.
A Framework for Action
To get back in control, you need a system. This guide lays out a straightforward framework designed for PMs to partner with their engineering counterparts and manage technical debt like a pro. It’s not about learning to code; it’s about learning to lead conversations that balance short-term wins with long-term product health.
Before we dive deep, here's a quick look at the system we'll be breaking down.
| A Quick PM Framework for Technical Debt | ||
|---|---|---|
| Phase | Objective | Key PM Action |
| Identify | Make all technical debt visible and understandable. | Collaborate with engineers to create a central, living catalog of debt items. |
| Quantify | Translate engineering problems into business impact. | Work with your engineering lead to estimate the "cost" of each debt item in terms of slowed velocity or risk. |
| Prioritize | Make strategic trade-offs between new features and debt reduction. | Integrate the highest-impact debt items directly into your product backlog and roadmap. |
This framework gives you a repeatable process for making smart, data-informed decisions.
The visual below breaks down the process into the three core, actionable phases we’ll explore in detail.
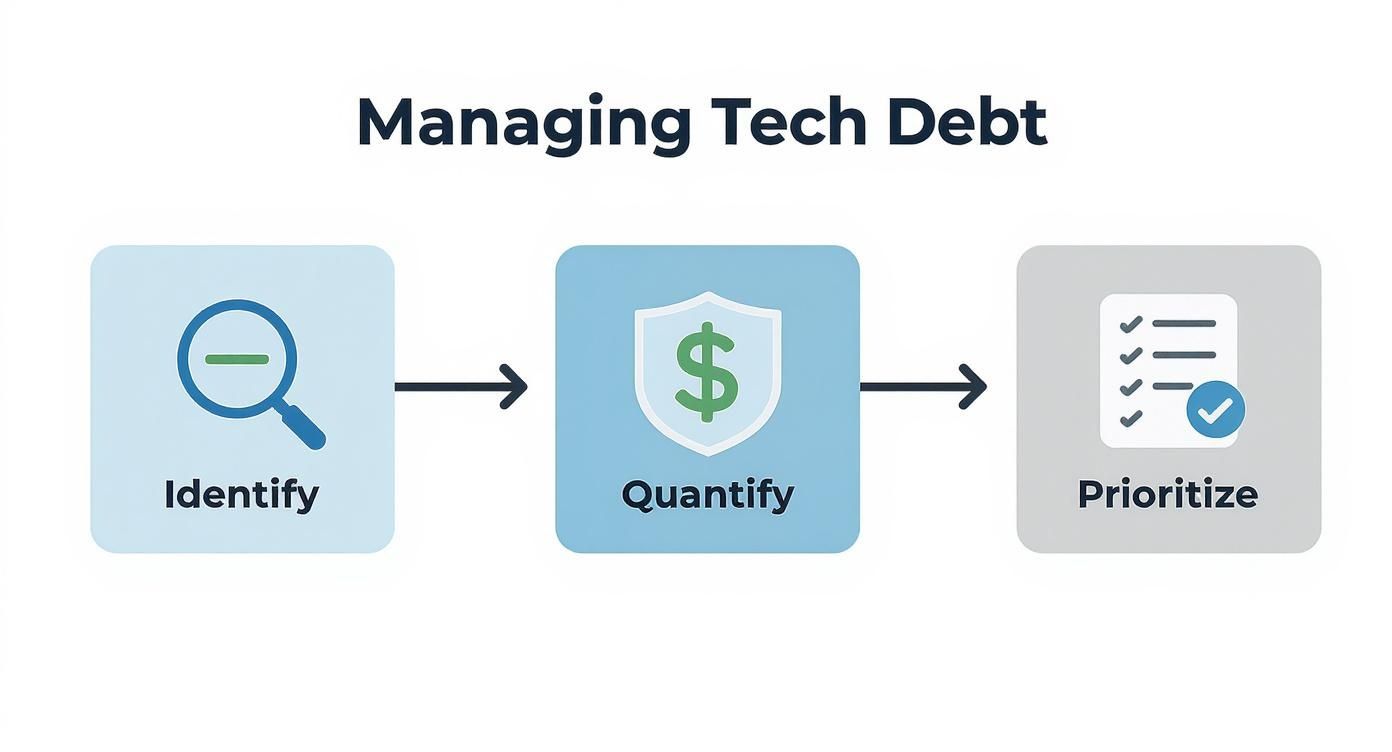
This workflow is all about making debt visible, translating it into business terms, and weaving it into your strategic planning.
By adopting a structured approach, you shift the conversation from a reactive cycle of complaints to a proactive, strategic one. You'll learn to speak the language of trade-offs, making informed decisions that serve both the immediate needs of the business and the long-term health of your product. This is how you level up from just managing features to truly leading a product.
Making Invisible Debt Visible with a PMs Audit Toolkit
You can’t manage what you can't see. As a Product Manager, your first and most critical job is to partner with your engineering lead to drag technical debt out of the shadows and into the light. It often feels like a murky, intimidating world of vague complaints, but with the right approach, you can turn it into a tangible, manageable backlog.
This process isn't about blaming anyone for past decisions. Far from it. It's about creating a shared understanding of the product's current reality. The goal is to evolve the conversation from "the codebase is a mess" to "this specific legacy service is slowing down feature development in our checkout flow by 30%." One is a complaint; the other is a problem you can solve.
The Four Quadrants of Technical Debt
To get started, you need a framework for what you find. Not all debt is created equal, and understanding its origin helps you figure out how to tackle it. I've always found Martin Fowler's Technical Debt Quadrant to be the most practical model for PMs.
It breaks debt down into four types:
- Deliberate and Prudent: This is strategic debt. You and the team consciously decide to cut a corner to hit a critical launch date for an MVP. You knew the code wasn't perfect, but the business value of speed outweighed the cost. This is perfectly acceptable, as long as it’s logged with a plan to repay it.
- Deliberate and Reckless: The team rushes and makes a mess, fully aware it’s a bad design, just to ship something without a clear strategic reason or a repayment plan. This is the real danger zone.
- Accidental and Prudent: This is the debt that accumulates when a great team makes the best possible decision with the information they have, only to discover a better approach later on. The original solution wasn't wrong; the team has simply learned more over time.
- Accidental and Reckless: This kind of debt piles up from junior teams or a lack of strong technical leadership. It results in a low-quality design that nobody realizes is bad until much, much later.
Understanding these categories helps you have a more nuanced conversation with your engineering counterparts. It moves the discussion beyond simple "good" vs. "bad" code arguments.
Uncovering Debt with the Right Questions
Your engineering team lives with this debt every single day. Your job is to create a safe, structured environment for them to bring their biggest pain points to the surface. Just asking "what's our tech debt?" is way too broad and won't get you far.
Instead, use your next 1-on-1 with your tech lead or a dedicated team session to ask targeted questions that get specific, actionable answers.
The quality of your technical debt audit depends entirely on the quality of your questions. Be specific and focus on friction. Your goal is to uncover the sand in the gears that slows everything down.
Here are some of the most effective questions I've used over the years:
- "If we had a two-week hackathon to fix anything in the codebase, no questions asked, what would you work on first?"
- "What part of the product do you absolutely dread getting a bug report for?"
- "Which part of our system makes you the most nervous during a new deployment?"
- "What's one thing that, if we fixed it, would immediately make your day-to-day work less frustrating?"
- "Where do we spend the most time on workarounds instead of building things the 'right' way?"
These questions have a knack for transforming abstract frustration into a concrete list of modules, services, and workflows that need attention.
Building Your Technical Debt Register
Once you start uncovering these issues, you need a central place to log everything. A simple spreadsheet works fine to start, but using a project management tool like Jira, Asana, or Notion is even better. It lets you integrate these items directly into your workflow. This becomes your Technical Debt Register.
This isn't just a list of complaints. Each entry needs to be documented with the context that you, as a PM, need to prioritize it effectively.
Your register should include columns for:
- Debt Item: A clear, concise name (e.g., "Legacy Checkout Payment API").
- Description: A simple, plain-English explanation of the problem.
- User Impact: How does this affect the end-user? (e.g., "Slow page loads," "random payment failures").
- Developer Friction: What's the impact on the team? (e.g., "Takes 3 extra days to add new payment options").
- Strategic Risk: What's the business risk? (e.g., "Security vulnerabilities," "Inability to partner with new payment providers").
Below is an example of how you might structure a project in Jira to track and manage these items, turning them into actionable tickets.
This visual shows how to create dedicated epics or tasks for debt items, which allows you to estimate effort and track progress just like any other feature.
Creating this register is a powerful first step in making data-driven decision-making a core part of your technical health strategy. You now have a shared, living document that translates engineering pain into a prioritized backlog you can discuss, debate, and tackle with your team.
Quantifying the Business Cost of Inaction
So you've done the audit. You have a neat list of all the technical gremlins lurking in your codebase. Now comes the part where most Product Managers completely fumble the ball.
They walk into a leadership meeting with a laundry list of technical problems. What do the executives hear? "We need to stop building new features and spend time and money on something that doesn't generate revenue." Unsurprisingly, the answer is often "no."
To get the resources you need, you have to stop talking like an engineer and start speaking the language of the business: dollars, risk, and time.
Your job is to completely reframe the conversation. You’re not asking for a budget to "clean up code." You're presenting a strategic investment with a clear, quantifiable return. The trick is translating that abstract technical friction into concrete business metrics that a CEO or CFO immediately gets.

This isn't just a small change in wording; it's a fundamental shift in strategy. It elevates your request from a low-level "fix-it" task to a high-level business decision, making it much, much harder to ignore.
The Feature Velocity Tax Model
One of the most powerful tools I’ve ever used to get buy-in is the Feature Velocity Tax. It’s a dead-simple way to calculate the percentage of your team's time being actively wasted because of a specific piece of tech debt. It puts a number on that feeling everyone has: "Why is everything so slow?"
Here’s the step-by-step process:
- Pinpoint a Debt-Ridden Area: Work with your tech lead. Pick a part of the product that everyone groans about working on. Think legacy checkout flows or an ancient reporting module.
- Estimate the 'Ideal' Time: Ask your engineers a simple question: "If this section were built cleanly today, without all the hacks and workarounds, how long would a typical 10-point story take?" Let’s say they come back with 4 days.
- Calculate the 'Actual' Time: Now, dig into your recent sprint data. "How long does a 10-point story actually take in this part of the codebase?" The real answer might be closer to 5 days.
- Calculate the Tax: The difference is your tax. In this scenario, it's 1 extra day for every 4 days of ideal work. The math is simple: (1 extra day / 4 ideal days) = 25% Velocity Tax.
Now, you take that percentage and turn it into something a stakeholder cares about.
How to Pitch It: "Our current checkout flow has a 25% Velocity Tax. For us, that means every four-week feature we plan to build there will actually take five weeks to get out the door. Our team's blended salary cost is about $120,000 per sprint. That one extra week costs us $30,000 in developer time and pushes our revenue goals back."
That single statement transforms a vague engineering complaint into a clear financial and opportunity cost. Suddenly, investing two sprints to fix the issue doesn't sound like a cost center. It sounds like a high-ROI investment. For more tips on building these kinds of compelling narratives for leadership, check out this detailed guide on how to present to executives.
Using the Bug Collision Rate
Another killer metric is the Bug Collision Rate. This is just a fancy name for tracking how often building a new feature in one place unintentionally creates bugs somewhere else entirely. A high collision rate is a classic symptom of tightly-coupled, brittle code—one of the most dangerous forms of tech debt.
To measure it, sit down with your QA and engineering leads and start tagging bugs by their origin. For example, when a new feature in the "Promotions Engine" causes a bug in the "User Profile" page, that’s a collision.
Presenting this data is incredibly powerful.
- Calculate the Rate: "Over the last quarter, we found that 40% of the bugs in our user profiles were actually caused by changes made outside of that module."
- Frame the Impact: "Our code is so tangled that changes in one area consistently break another. This not only doubles the testing time for every new feature but also erodes user trust when random bugs pop up in stable parts of our product."
This metric hits on product quality and predictability, two things every executive team is obsessed with. It proves that inaction isn't just slowing you down; it's actively degrading the customer experience.
And this financial burden isn't just your problem; it's a massive issue across the industry. Some research shows that technical debt can account for up to 40% of a company's total technology assets, with businesses often spending over a quarter of their IT budgets just trying to manage it. The Consortium for Information & Software Quality estimates this costs US companies a staggering $2.41 trillion every single year. You can read the full research about these technical debt findings to get more context on the scale of this problem.
Prioritizing Debt in Your Product Roadmap
So, you’ve done the hard work of auditing and quantifying your technical debt. You have a running list of issues and, more importantly, the data to show what it’s costing the business if you do nothing. Now comes the million-dollar question every PM has to answer: what do we fix, and when?
A common rookie mistake is to just block off a “tech debt sprint.” This treats debt like some isolated chore to be dealt with separately. But in reality, it's a living, breathing part of your product's ecosystem. The best product leaders I’ve seen don't just manage debt; they strategically weave it into the very fabric of their product roadmap.

This means you need a pragmatic way to prioritize that balances the real business value of a fix against the engineering effort required to do it. You're not just cleaning up code for the sake of it. You're making calculated investments of your team's time to get the biggest return for the business.
A PM's Prioritization Matrix for Debt
The trick is to get beyond a simple "fix" or "don't fix" mentality. You need a system that lets you compare something like a legacy API refactor against a shiny new user-facing feature. I've always leaned on a simple matrix that scores debt items on a few business-centric axes versus the engineering effort.
For each item on your debt register, score it from 1 (low) to 5 (high) on these criteria:
- Customer Experience Impact: How directly is this hurting the user? Think slow load times, frustrating bugs, or a clunky checkout flow. A high score means your users are actively feeling the pain.
- Revenue Risk: Does this debt threaten your ability to make money? This could be a flaky payment processor, a security hole that could lead to fines, or instability that puts your SLAs with big clients at risk.
- Developer Morale / Velocity Impact: How much does this specific issue slow the team down and just crush their spirits? This is the "dread factor"—the parts of the codebase engineers avoid because they’re tangled and brittle.
- Estimated Engineering Effort: How many story points or developer-weeks will it take to fix this thing properly? This is your cost.
Once you score each item, you can plot them on a matrix to get a clear visual of your priorities. You're looking for the high-impact, low-effort quick wins and a plan for the high-impact, high-effort strategic projects.
The most critical skill in managing technical debt is distinguishing between an engineering inconvenience and a genuine product risk. A poorly written backend service that works reliably is a low priority. A slow, buggy onboarding flow that causes a 15% drop-off is a product emergency.
To make this crystal clear, I've put together a simple table that summarizes this framework. Think of it as a cheat sheet for making tough calls.
Technical Debt Prioritization Matrix
This visual framework helps PMs decide which tech debt items to tackle first by mapping business impact against engineering effort.
| Priority Level | Business Impact | Engineering Effort | Example Action |
|---|---|---|---|
| P1: Quick Wins | High | Low | Fix immediately. These are high-ROI tasks that unblock the team or improve user experience with minimal dev time. |
| P2: Strategic | High | High | Plan for these. Schedule them in the roadmap as major initiatives, breaking them down into smaller, manageable chunks. |
| P3: Fill-in Tasks | Low | Low | Address when time allows. Good candidates for when there are small gaps between bigger projects. |
| P4: Avoid/Monitor | Low | High | Acknowledge and monitor. The cost to fix outweighs the benefit. Re-evaluate if the business impact changes. |
Using a matrix like this turns subjective debates into objective, data-informed decisions, which is exactly where a PM adds the most value.
Real-World Prioritization Scenarios
Let's make this tangible. Imagine you're the PM for an e-commerce platform and these two items are on your debt register:
Scenario A: Slow, Buggy Onboarding Flow
- Customer Impact: 5/5 (Users are abandoning signup in droves)
- Revenue Risk: 4/5 (Directly killing new user acquisition and their first purchase)
- Developer Morale: 3/5 (Frustrating, but the code is generally understood)
- Effort: Medium (Needs 2 engineers for one sprint)
Scenario B: Refactor Backend Order Service
- Customer Impact: 1/5 (The service works; users see zero issues)
- Revenue Risk: 2/5 (There's a risk if it fails, but it's been stable)
- Developer Morale: 5/5 (Engineers hate the old code; it's a huge drag on adding new shipping partners)
- Effort: High (The whole team would need two full sprints)
With this framework, the choice is obvious. The onboarding flow is a burning product problem that needs to be prioritized right now. The backend refactor, while important for long-term velocity and morale, is a strategic project you can schedule for a future quarter. This gives you a clear, logical rationale for your decisions that even non-technical stakeholders can get behind.
This method of weighing impact against effort is a core principle you'll find in any solid guide on how to prioritize a roadmap, because it applies just as well to tech health initiatives as it does to new features. When you treat debt items as first-class citizens in your backlog and score them with the same rigor, you ensure the health of your product is never an afterthought.
Building a Sustainable Debt Management Cadence
Tackling technical debt isn't a one-and-done project. It’s a cultural shift. The real win comes when you move your team away from reactive, panic-driven fire drills and into a proactive, predictable rhythm of managing product health. The goal is to weave debt management so deeply into your team's regular operations that it becomes as second nature as sprint planning.
This isn't about blowing up your feature roadmap for a "clean-up quarter." It’s about making small, consistent investments that prevent severe debt from piling up in the first place. This proactive stance is what protects your product's future velocity and builds a lasting culture of quality and ownership.

A steady, sustainable approach also does wonders for team morale and productivity, helping to prevent employee burnout. When engineers aren't constantly wrestling with a decaying codebase, they have the creative energy to focus on high-impact work.
The 20% Rule Model
One of the most battle-tested models for creating this rhythm was made famous by companies like Google. The 20% Rule is beautifully simple: you allocate a fixed percentage of every sprint's capacity—usually 10-20%—exclusively to tech health initiatives.
This isn't just "buffer time" that can be snatched away. It's a non-negotiable budget for paying down the debt you've already prioritized. This model treats technical debt as a first-class citizen in the backlog, with dedicated time carved out for it.
The data backs this up. One report found that companies dedicating 10-20% of each sprint to debt see a 25-30% boost in delivery speed and a 20% cut in maintenance costs within the first year.
Pros of the 20% Rule:
- Consistency: It creates a steady, predictable pace of improvement, which is key to preventing debt from ever spiraling out of control.
- Flexibility: The team can knock out small-to-medium debt items without needing a massive roadmap disruption.
- Stakeholder Simplicity: It’s a straightforward sell to leadership: "We invest one day a week in keeping our engine running smoothly so we can go faster."
Cons of the 20% Rule:
- Discipline Required: It’s incredibly tempting to "borrow" this time for an urgent feature request. As a PM, you have to fiercely protect this allocation.
- Not for Large-Scale Debt: It’s less effective for the massive, architectural refactors that require the whole team's focused effort over multiple sprints.
The Alternating Sprints Model
For teams staring down a more significant, concentrated mountain of debt, the Alternating Sprints model often makes more sense. Here, teams cycle between different types of sprints. A common pattern is three feature-focused sprints followed by one dedicated "health" or "foundations" sprint.
This approach gives the team permission to fully concentrate on complex refactoring or infrastructure upgrades without the constant context-switching of juggling feature work. It’s an ideal way to tackle those P2 Strategic initiatives we identified in the prioritization matrix.
Choosing the right cadence isn't about finding a perfect formula. It's about matching the model to your team's culture, product maturity, and the specific type of debt you're facing. The key is to commit to a system and stick with it.
Here’s a quick comparison to help you decide which model might be a better fit for your team.
| Feature | 20% Rule Model | Alternating Sprints Model |
|---|---|---|
| Pace of Debt Reduction | Slow and steady | Bursts of high-impact work |
| Best For | Ongoing maintenance, small fixes | Large refactors, migrations |
| Impact on Roadmap | Minimal, consistent "tax" | Predictable, larger "pauses" |
| PM's Role | Protect the allocation sprint-to-sprint | Plan and sequence major health initiatives |
Ultimately, both models achieve the same goal: they make paying down technical debt a non-negotiable part of your product development lifecycle. By establishing this cadence, you’re not just fixing old code; you’re building a resilient, high-performing product organization that can sustain innovation for the long haul.
Common Questions About Managing Technical Debt
Over the years, I've noticed the same questions about technical debt come up again and again from PMs I've hired and mentored. Let's cut through the noise and get straight to the no-fluff answers you'll need in your career.
How Do I Convince Stakeholders to Invest in This?
Stop talking about technology. Start talking about business metrics.
When you say things like "refactor the payment service," you can practically see the eyes of non-technical leaders glazing over. To them, it sounds like an internal engineering problem with zero clear customer benefit. It's just noise.
You have to translate the problem into their language. That means framing it with data and, when you can, a solid analogy.
Don't Say: "We need two sprints to refactor the payment service because the code is messy."
Say This Instead: "Our current payment service architecture adds three days of development time to any new feature in that area and contributes to a 5% higher checkout abandonment rate due to slow performance. Investing two sprints to fix this will boost our feature velocity by 15% and could recover $50,000 in monthly revenue."
See the difference? You just reframed the request from a cost center into a high-ROI investment opportunity. You’re not just fixing code; you're buying back future development time and directly improving a core business metric.
Analogies also work wonders. I like to compare tech debt to running a restaurant with old, inefficient kitchen equipment. Sure, you can keep working with it, but every order takes longer and you're making more mistakes. Suddenly, the need for an upgrade becomes obvious to everyone.
Is All Technical Debt Bad?
Absolutely not. In fact, deliberately taking on technical debt can be a savvy, strategic move.
Think about it. When you're racing to launch an MVP to validate a core hypothesis, or trying to beat a competitor to a critical market window, taking a documented shortcut is often the right call.
This is what we call strategic debt. The key is that it's a conscious, calculated decision made by both product and engineering, with a clear plan to address it later. You’re essentially taking out a short-term loan for a significant business gain.
The real danger comes from accidental debt—the kind that accumulates slowly and silently from a lack of clear standards or just plain reckless corner-cutting. As a PM, your job is to facilitate the conversation about when to take on strategic debt and ensure it’s logged and prioritized for repayment, just like any other business loan.
What Is the Difference Between a Bug and Tech Debt?
Getting this distinction right is crucial for prioritization, and it trips up a lot of new PMs. A bug is a specific, observable failure where the product doesn't work as designed. Technical debt is the underlying, systemic issue in the code that makes bugs more likely and features harder to build.
Here's a simple way I explain it to my teams:
- Fixing a Bug: This is like patching a single pothole on a busy road. It’s a tactical, often urgent fix for an immediate problem. Quick and reactive.
- Addressing Tech Debt: This is like repaving the entire road. It’s a strategic, foundational investment that prevents future potholes from forming easily and makes the road smoother for all future traffic. Proactive and foundational.
Both require your attention, but you have to understand the difference in impact. A bug fix is a reactive solution to a known problem. A tech debt initiative is a proactive investment in your product's long-term health and your team's future velocity.
Ready to level up your product leadership skills? Aakash Gupta provides in-depth guides, podcasts, and coaching to help you master challenges like managing technical debt and accelerate your career. Get the insights you need at https://www.aakashg.com.