A weak product idea usually sounds fine until someone asks the obvious question.
“We should add social sharing to article pages.”
“Why?”
“It should help engagement.”
That exchange kills momentum in roadmap reviews because the idea isn't wrong. It's just unfinished. The team hasn't said what will change, what result they expect, or why they believe it. Engineering hears ambiguity. Leadership hears risk. Analytics hears future confusion.
The If Then Because hypothesis fixes that fast. It turns a loose feature idea into a testable product bet. For PMs, that makes it more than a science-class template. It becomes a communication tool for product reviews, experiment design, AI model evaluation, and stakeholder alignment.
When teams skip this step, they confuse activity with learning. They build features, launch them, and then argue about what the results mean. Good product discovery habits start earlier. They start when you force an idea into a form that can be wrong.
Your Antidote to Vague Product Ideas
Most PMs don't struggle because they lack ideas. They struggle because too many ideas arrive in strategy meetings as half-formed opinions.
A designer says users need more delight. A growth lead wants another lifecycle email. An exec points at Spotify or Netflix and says, “They personalize everything. We should do more of that.” None of those are usable on their own. They don't define the change, the expected outcome, or the mechanism.
That's where the If Then Because hypothesis earns its keep. It gives you one sentence that can survive scrutiny.
What weak ideas sound like
Here are the versions I see all the time:
- Feature-first thinking: “We should add a recommendation carousel.”
- Metric fog: “This should improve engagement.”
- Cargo-cult product strategy: “Netflix does this, so we should too.”
- Post-rationalized roadmaps: “Let's build it and see what happens.”
Every one of these creates the same downstream mess. Design explores too broadly. Engineering estimates the wrong scope. Data teams don't know what success looks like. Stakeholders later pick whichever metric supports their opinion.
Vague ideas don't fail only because the feature is bad. They fail because no one agreed on what was being tested.
What stronger thinking looks like
A PM using this framework might say:
- If we add article sharing prompts after the reader reaches the end of an article,
- then we expect more readers to share content externally,
- because readers are most likely to act after they've finished consuming the piece and found it useful.
That statement still needs sharper measurement, but it's already better. It frames a decision the team can debate intelligently.
The hidden benefit is strategic. Once teams write ideas this way, meetings get shorter and better. You stop debating whose intuition feels strongest and start asking whether the rationale is strong enough to merit a test.
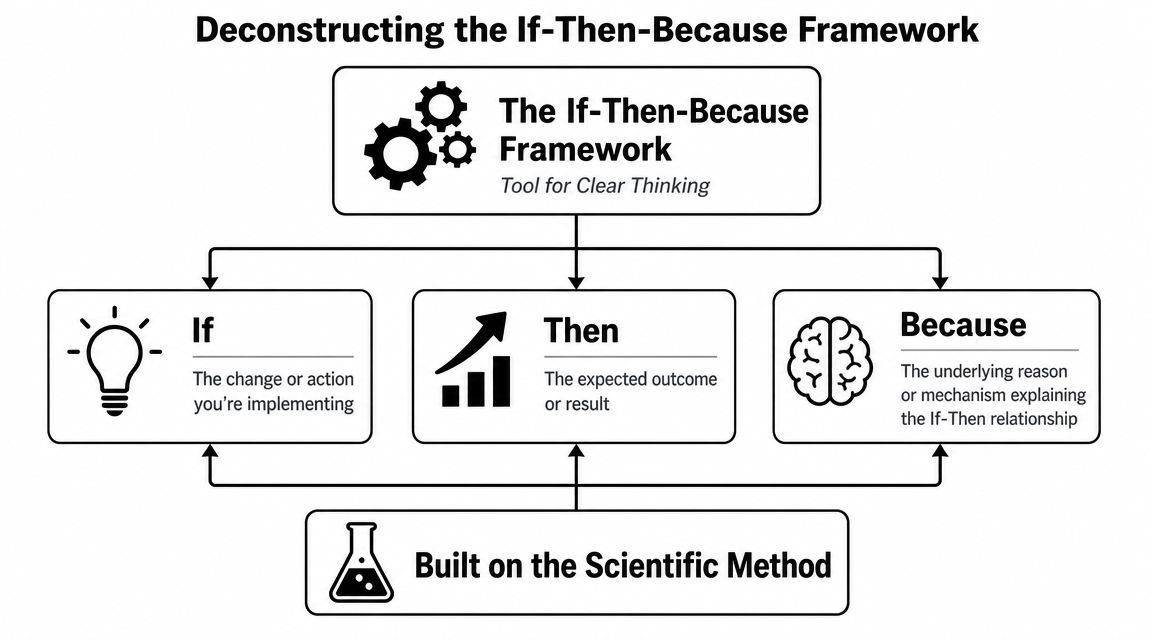
The If-Then-Because Framework Deconstructed
The framework is simple, but teams often use it loosely. They treat it like a fill-in-the-blank sentence instead of a discipline for clear thinking.
Research-method guidance describes the structure this way: the “if” clause introduces the testable condition, the “then” clause states the expected result, and the “because” clause explains the causal rationale. That separation matters because it keeps teams from presenting speculation as evidence, and it forces them to ground the hypothesis in prior evidence rather than guesswork, as noted in John Measey's guidance on how to write a hypothesis.
If you want a stronger standard for product experimentation, this guide on what makes a good hypothesis is a useful companion.
The If clause
The If is the thing you will change. In experimental terms, it represents the independent variable.
In product work, that might be:
- changing onboarding from four steps to three
- introducing a new ranking model in search
- adding a “continue watching” row on a streaming home page
- moving a pricing CTA higher on the page
The key is singularity. If your If contains three different changes, you're no longer testing a clear idea.
The Then clause
The Then is the result you expect to observe. This is your dependent variable, the thing you'll measure.
Good Then clauses sound like this:
- more users complete onboarding
- fewer users abandon checkout
- more listeners save recommended tracks
- more viewers start a second episode
Bad Then clauses sound like this:
- users will like it more
- the experience will feel smoother
- the feature will be more useful
Those may be aspirations, but they aren't operational.
The Because clause
The Because is where average PMs separate from strong ones. This is the mechanism. It explains why the change should produce the result.
A weak rationale says, “because it's more visible.”
A stronger rationale says, “because new users currently miss the setup action during their first session, and reducing search effort should improve completion.”
Practical rule: If your “because” could be replaced with “just because,” you don't have a real hypothesis yet.
That's why the framework is powerful. It separates prediction from mechanism. The team can agree that a metric may move while still challenging whether the reasoning is sound.
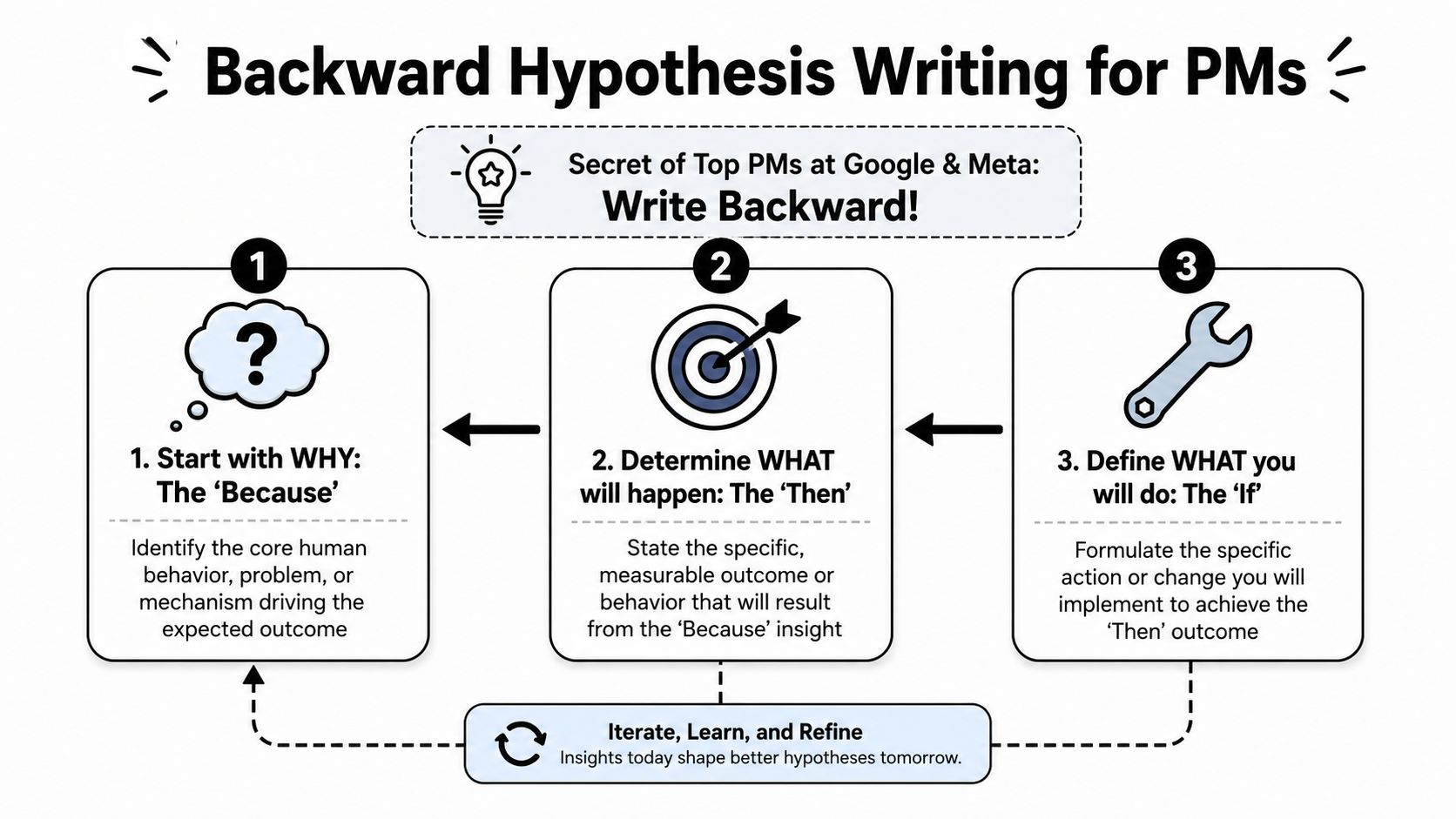
How to Write Strong Hypotheses Step-by-Step
Most PMs write hypotheses in the order they speak them. They start with If, jump to Then, and tack on a thin Because at the end.
That usually produces weak thinking. The better move is to write backward. Start with the rationale. Then decide what outcome would prove that rationale useful. Only then define the smallest product change worth testing.
A stronger standard for the because clause is to frame a testable causal question and, when possible, define the hypothetical experiment, expected outcomes, and success criteria rather than rely on a vague intuition, as discussed in this methodological review on rigorous hypothesis framing.
Start with Because
Your Because should come from somewhere real:
- user interview patterns
- support tickets
- onboarding session replays
- failed activation attempts
- prior experiment learnings
- domain knowledge about behavior
For example, suppose your AI PM team wants to improve a support copilot. Don't begin with “If we switch models.” Begin with the core belief:
Customers abandon the assistant when it returns long answers before clarifying intent. They want faster narrowing, not broader verbosity.
That's a useful Because. It contains a mechanism you can test.
Define Then before If
Once you know the mechanism, define what observable behavior should follow if you're right.
For the support copilot example, Then might be:
- more users complete a support flow through the assistant
- fewer users escalate to a human immediately
- more users ask a second follow-up question
Notice what's happening. You're tying the hypothesis to behavior, not vibes.
Finish with the smallest If
Now define the smallest intervention that can test the belief.
Instead of rebuilding the whole assistant, you might:
- add a clarifying question before answer generation
- shorten the initial response
- show top intent categories before free text
That keeps cost and ambiguity low.
Here's a practical template:
- Because: What user behavior or system dynamic do we believe is driving the current problem?
- Then: What measurable behavior should change if that belief is correct?
- If: What is the smallest product, UX, or model change that tests it?
Don't fall in love with the implementation. Fall in love with finding out whether the mechanism is real.
A useful way to pressure-test your logic is to ask a technically minded partner to challenge it. PMs who also want to prepare for coding interviews often benefit from that same style of rigorous thinking because it trains you to define assumptions precisely instead of hand-waving over them.
When the rationale still feels fuzzy, I often ask teams to write down the underlying assumption behind the idea before writing the hypothesis itself. That usually exposes whether the proposal is grounded in observed behavior or in wishful thinking.
A rewrite example
Weak version:
- If we add a social graph feed, then users will engage more, because social experiences are sticky.
Strong version:
- Because many new users don't know what to do after account creation and respond better when shown activity from people they follow,
- then more new users should return for a second session,
- if we show a lightweight follow-and-feed experience immediately after signup.
That version isn't perfect yet, but the team can now work with it.
Real-World PM Hypothesis Templates and Examples
Theory helps. Templates get used.
A good if then because hypothesis should always make the variable you change distinct from the variable you measure. Instructional guidance on testable hypotheses makes this explicit: a correct hypothesis must include an independent variable and a dependent variable, which is what turns cause-and-effect logic into something measurable, as explained in this overview of formatting a hypothesis.
Quantitative A B test
This is the standard PM use case.
| Version | Example |
|---|---|
| Weak | If we make the button green, then more people will click it, because green stands out. |
| Stronger | If we change the primary checkout CTA from blue to green for first-time purchasers, then more visitors should complete the next step in checkout, because the current CTA blends into surrounding interface elements and may be missed during rapid scanning. |
Why the stronger version works:
- The If is specific: one button, one context, one audience.
- The Then is observable: next-step completion.
- The Because points to behavior: visual discoverability, not color superstition.
Qualitative discovery test
Not every hypothesis needs an A/B test. Discovery work needs hypotheses too.
Weak version:
- If we build collaborative trip planning, users will want it, because travel is social.
Stronger version:
- If we show frequent planners a clickable prototype for collaborative itinerary editing during user interviews, then they should describe replacing current coordination workarounds with the feature, because today they manage plans across fragmented tools like messages, docs, and screenshots.
This is still testable even without production traffic. The dependent variable here is qualitative evidence: do users map the concept to a real current behavior, or do they just say it sounds nice?
AI model test
AI PMs need this framework even more than classic SaaS PMs because model improvements can look impressive offline and still fail in-product.
Weak version:
- If we deploy a new recommendation model, then session length will improve, because the model is smarter.
Stronger version:
- If we use a recommendation model that increases diversity within a user's familiar taste boundaries on the home feed, then more users should start a second piece of content from recommendations, because overly repetitive recommendations create fatigue while overly novel recommendations reduce trust.
That's the kind of hypothesis Spotify or Netflix teams can debate. The model change is clear. The user behavior is measurable. The mechanism is behaviorally plausible.
Good AI PMs don't ship “better models.” They ship hypotheses about user behavior mediated by models.
A reusable template
Use this when drafting with your team:
- If we change [specific product behavior, UI, workflow, or model]
- then [specific user behavior or business outcome] should change
- because [evidence-based mechanism tied to observed user behavior]
Add these notes under it:
- target user segment
- primary success metric
- guardrail metrics
- time window for evaluation
- what would falsify the hypothesis
That last line matters more than many groups acknowledge.
Validating Your Hypothesis and Measuring Success
A hypothesis isn't useful until the team decides how it will be judged.
Many PMs tend to get sloppy at this point. They write a decent If Then Because statement, launch the change, and then rummage through dashboards to find a narrative. That's not validation. That's improvisation.
The better approach is to connect the Then clause directly to one primary KPI and a small set of guardrails. If your hypothesis says onboarding completion should improve, define exactly how completion is measured, for which cohort, over what time period, and what would count as noise versus signal.
For a broader framework on de-risking ideas before full investment, this guide on testing business ideas is worth keeping in your toolkit.
Pick one success metric and protect it with guardrails
A clean experiment usually has:
- One primary metric: the thing your Then clause predicts
- A few guardrails: metrics that shouldn't get worse while the primary metric improves
- A decision rule: launch, iterate, or stop
Examples:
| Scenario | Primary metric | Guardrails |
|---|---|---|
| Checkout change | step completion | refund rate, support contacts |
| Onboarding simplification | setup completion | activation quality, retention |
| AI support assistant | task resolution through assistant | escalation rate, user complaint signals |
A common trap is picking a proxy because it's easy to measure. Don't say the goal is retention and then judge success by clicks unless you're explicit that clicks are only an early indicator.
Decide what invalidation means
Strong teams define failure before launch.
If the metric doesn't move, the hypothesis may be wrong. If the metric moves but guardrails worsen, the hypothesis may be too narrow. If a secondary metric improves while the primary one doesn't, you may have learned something useful, but not what you set out to prove.
A falsified hypothesis is often more valuable than a vague success. It saves roadmap space.
This matters in leadership settings. A PM who says, “The test did not validate our belief, so we should not scale this,” sounds far more strategic than one who tries to rescue every experiment with spin.
Treat outcomes as decision inputs
Once results come in, ask three questions:
- Was the predicted outcome observed?
- Did it happen for the reason we proposed, or is there another explanation?
- What decision follows now?
That final step is where experimentation earns trust. A hypothesis is only as good as the decision discipline that follows it.
Common Hypothesis Mistakes PMs Make
The most common mistakes aren't dramatic. They're subtle enough to survive meetings and still wreck learning.
One of the biggest is confusing a hypothesis with a prediction. Academic guidance distinguishes the two clearly: a hypothesis is the causal answer to the research question, while a prediction is what you would observe if that hypothesis were true, as explained in Trent University's guide to understanding hypotheses and predictions.

Mistake one, the tautology
This sounds smart but says almost nothing.
Bad version:
- If we make the button bigger, then more users will click it, because a bigger button is more clickable.
The Because just repeats the If. It adds no mechanism.
Better version:
- If we increase the size and contrast of the primary action on mobile, then more users should start the next step, because many users currently scan past the action when the page is visually dense.
Mistake two, the unmeasurable outcome
PMs often write “users will be happier” or “the experience will feel better.”
That may be directionally true, but it's not enough for a test. Translate it into behavior or observation.
Try this instead:
- complete setup faster
- return for another session
- contact support less often
- complete a task with fewer errors
Mistake three, the bundled If
A hypothesis can't survive if the intervention is a bundle.
Bad version:
- If we redesign onboarding, improve the homepage, and add better email reminders, then activation will improve.
If activation improves, you won't know why. This is one reason many teams think they're data-driven when they're just running expensive ambiguity.
Mistake four, the empty Because
This one is especially common in AI work.
Bad version:
- If we deploy a larger model, then answer quality will improve, because the model is more advanced.
That's not a mechanism. It's a status claim.
A useful Because should point to something behavioral, structural, or task-specific. For example, the new model may better preserve context across longer exchanges, which could reduce user reformulation.
Weak hypotheses hide assumptions. Strong hypotheses expose them so the team can attack them early.
A quick self-check
Before you approve a hypothesis, ask:
- Can one person point to the exact variable being changed?
- Can the data team identify the dependent variable immediately?
- Does the Because explain a mechanism instead of restating the prediction?
- Could the statement be proven wrong?
If the answer to any of these is no, it needs another pass.
From Hypothesis to Product Strategy
The best PMs don't use the If Then Because hypothesis only for experiments. They use it to shape roadmaps.
That's because the format is a modern shorthand for the hypothetico-deductive method, and research guidance notes that universities and research organizations have standardized it to make studies falsifiable and reproducible, which is why it's a durable convention rather than just a classroom mnemonic, as discussed in this paper on the scientific method and hypothesis structure.
Why this matters beyond experimentation
A roadmap is really a stack of beliefs about customer value, business value, and execution risk.
When a PM presents roadmap items as hypotheses, several things improve fast:
- leaders can debate assumptions instead of personalities
- engineering sees where uncertainty is highest
- design knows which user behavior matters most
- data teams can instrument before launch
- AI teams can separate offline model gains from real product impact
This is also how you de-risk launches. A thorough Saaspa.ge product launch resource can help teams operationalize rollout planning, but the launch itself is stronger when every major workstream traces back to a testable product belief rather than a feature wish list.
For PMs building their own planning muscle, a solid product strategy framework helps connect individual hypotheses to portfolio-level bets.
The career signal
People notice PMs who communicate this way.
They sound crisper in reviews. They waste fewer cycles. They know when to push forward and when to kill an idea. That's not just experimentation maturity. That's strategic judgment.
In AI product management especially, this skill is becoming table stakes. Model capability changes quickly. The PM who wins isn't the one who says “the model got better.” It's the one who says, “Here is the user behavior we expect to change, here is why, and here is how we'll know.”
If you want more practical PM frameworks, experiment templates, and product leadership guidance, explore Aakash Gupta. His site includes resources on hypotheses, strategy, growth, and the day-to-day craft of becoming a stronger Product Manager.